

Accelerating Radar Cross-Section Calculations with Altair Solutions on HPC Clusters from Hewlett Packard Enterprise
In advance of the 2021 Supercomputing conference, Altair and Hewlett Packard Enterprise (HPE) teamed up to deliver a ground-breaking new benchmark. While computing radar cross-sections (RCS) may seem exotic to some, electromagnetic simulations are a fast-growing area in high-performance computing (HPC). After all, electromagnetic simulation is used in everything from consumer electronics, to evaluating radiation safety, to 5G network design and more. Keep reading to learn about our recent RCS benchmark and why this result is important for a variety of similar HPC problems.
About Radar Cross-Sections
A radar cross-section is a measure of how detectable an object is by radar. The RCS of an aircraft is often expressed as the signal power returned by an object relative to a theoretical perfectly conducting sphere representing a 1m2 return. For example, the RCS of a jumbo jet is approx. 100m2. By contrast, an F/A-22 fighter jet viewed head-on has an RCS roughly the size of a marble.1
While military applications are obvious, RCS and scattering analysis have applications in other fields, too. These include flight tracking, seaborne shipping, and monitoring bird movements and other aviation hazards near commercial airports.
A Compute-Intensive Problem
Calculating RCS involves complex physics. The strength of a returned radar signal depends on various factors, including the size of the object, its material, orientation, distance relative to the transmitter, and the power and wavelength of the illuminating radar signal.
When simulating RCS, reflections from objects are computed from multiple angles and elevations. This can translate into thousands of discrete simulations and take hours, if not days to compute -- even on powerful HPC clusters. Also, depending on the object’s orientation and geometry, signals will “bounce,” which results in multiple reflections (radar returns) from the same incident wave.
As if this wasn’t complicated enough, some structures are enormously challenging to model - for example, a jet that has an air inlet with a rotating fan presents complex geometry. It’s tempting to skip over such details. However, these physically small features can have disproportionately large radar signatures, which makes them impossible to ignore. Engineers frequently use multiple simulation methods accurately model RCS.
Altair® Feko®
Altair Feko is a versatile, high-frequency electromagnetic simulator that’s used in various industries, including aerospace, defense, automotive, and consumer electronics. Feko has several advantages over other electromagnetic solvers and provides:
- A comprehensive set of solvers optimized to different simulation requirements - MoM, MLFMM, LEPO, RL-GO, and more2
- A simplified end-to-end workflow, from geometry modeling, to advanced data manipulation and visualization
- Extreme scalability with a highly parallel solver and a model pre-processor for efficient, HPC-friendly simulations
The RCS Benchmark
To demonstrate the power of Feko running on a powerful HPC cluster from HPE, we undertook two RCS calculations involving the same model of a Lear Jet. The Lear Jet was comprised of 461,437 elements, was 17.08 meters in length, 13.71 meters in width, and 3.46 meters in height measured from extreme points in the aircraft. The simulation involved evaluating the RCS from multiple angles across a 180-degree arc. 473 points were simulated across this range (every 0.381 degrees of arc). For simplicity, the simulation assumed a constant elevation and a fixed transmitter frequency of 1 GHz for a wavelength (λ) of 30 cm. The model was run in two different ways:
- Scenario one: a single large simulation across 128 cores with no workload manager. First, the simulation was run as a single large parallel MPI job consisting of 128 ranks/processes to establish a baseline.
- Scenario two: a “farmed result” comprised of 32-way MPI jobs managed by Altair PBS Professional. In this scenario, the model was run on the same hardware environment. However, in this case, Altair Feko sub-divided the simulation into multiple discrete 32-way MPI jobs so that they could be efficiently dispatched to an HPC cluster using PBS Professional.
The Hardware and Software Environment
For consistency, both tests were run on the same HPE cluster comprised of four compute hosts. Each dual-socket compute host had 128 GB of physical memory and was populated with two Intel® processors with 18 cores each.3 Nodes were connected via a high-performance Aries dragonfly interconnect and shared Lustre parallel file system.4 The test environment for the second scenario is pictured below.
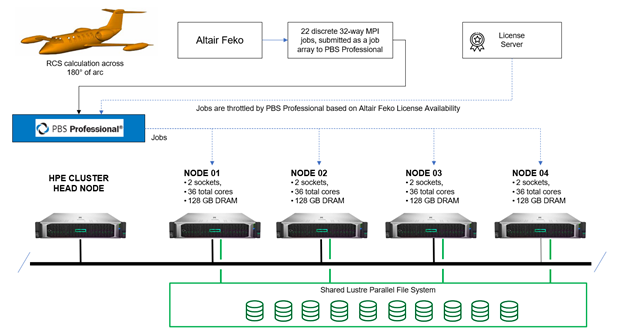
Both tests were run using the Feko version 2021.1.1 parallel solver with Intel MPI. The rigorous MLFMM method was used to simulate the RCS. In the first scenario, the simulation was launched as a single job using mpirun, calculating all 473 angles in sequence. In the second scenario, the simulation was structured as 22 discrete 32-way MPI jobs, each managed by the PBS Professional workload manager in a job array. PBS Professional throttled jobs based on Feko license availability to avoid failures at runtime due to software licenses becoming oversubscribed.
HPE and PBS Professional Deliver Superior Throughput
The Altair / HPE benchmark results proved the wisdom of the adage “work smarter, not harder.” Structuring the simulation to run as a series of jobs managed by PBS Professional delivered superior performance, as illustrated below.
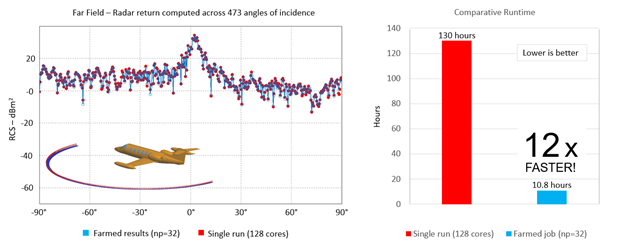
Calculating the RCS of the Lear Jet using a single 128-way MPI job took ~130 hours running across four nodes, each with 36 cores and 128GB of physical memory. Running the same simulation with Altair PBS Professional, restructured to run as multiple smaller 32-way MPI jobs, took 10 hours and 48 minutes – a ~12x performance gain.
While it may seem counterintuitive that a simulation can run 12 times faster on the same hardware, there are reasons it can. For example, some models are too small to make use of all the resources in a large cluster. This is the case with this simulation – by comparison, running a single large job is inefficient.
Better performance is achieved by running a series of 32-way jobs, each covering a subset of the RCS simulation angles. This is because the smaller 32-way job kept all hardware cores utilized. Also, latency was reduced dramatically since PBS Professional placed each 32-way job on a single host, avoiding the need for MPI ranks to communicate across external networks.
Another advantage of running the Feko simulations under PBS Professional is that execution becomes more reliable and predictable. Suppose a job were to fail at runtime – in that case, it’s more efficient to have the scheduler automatically restart a single element in a job array than restart or resume a large parallel job from a previous checkpoint. In the clustered environment, licenses were a limiting factor. Had more licenses been available, the cluster-based simulation could have run across more nodes and may have completed even faster than the observed 10.8 hours.
PBS Professional and HPE – An ideal combination for Altair Feko simulations
PBS Professional is a fast, powerful workload manager that improves productivity, optimizes efficiency, and simplifies administration across clusters, clouds, and supercomputers. With sophisticated support for MPI parallel jobs, job arrays, and throttling jobs based on license availability, PBS Professional is an ideal scheduler for optimizing the performance of RCS and other electromagnetic simulations.
Fast throughput is critical to accelerating HPC intensive codes such as those found in Feko. By combining MPI parallel jobs, job arrays, and license-aware scheduling, PBS Professional helps to maximize performance and resource utilization on HPE systems delivering faster, higher quality results that maximize customer value.
Tony DeVarco – HPC, manufacturing segment manager, Hewlett Packard Enterprise
Altair, together with HPE, the world’s leading HPC solutions provider, have been partnering for over a decade, delivering powerful HPC capabilities for customers to support a wide range of applications, and at scale. HPE’s HPC solutions range from small clusters to high-end supercomputing, such as for exascale-class supercomputers, and deliver end-to-end compute, software, interconnect, and storage capabilities. This range of offerings makes high-performance computing, highly dense storage, integrated cluster management, and rack-scale efficiency available to organizations of all sizes. HPE provides customers with a holistic, integrated HPC cluster with options for full support from HPE Pointnext services that can all be delivered as a cloud service through the HPE GreenLake edge-to-cloud platform.
As these recent Feko simulations confirm, Altair HPC tools on HPE systems allow customers to work smarter – not harder – and deliver exceptional results for electromagnetic simulations.
Learn more about Altair FEKO by visiting https://www.altair.com/feko/.
Learn more about HPE’s HPC solutions at https://www.hpe.com/us/en/compute/hpc.html.
Learn more about Altair PBS Professional at https://www.altair.com/pbs-professional/.
1. See GlobalSecurity.Org - Radar Cross Section (RCS)
2. MoM refers to a rigorous “methods-of-moments” technique widely used RCS solution. MLFMM, also a rigorous technique, refers to “multi-level fast multiple methods”. Altair offers two proprietary asymptotic simulation methods that can deliver excellent accuracy with a small fraction o the compute requirement – Large Element Physical Optics (LEPO) and RL-GO (Ray Launching Geometrical Objects).
3. The benchmark was run with hyperthreading disabled as is common for HPC workloads.
4. The Machine used for the benchmark was a powerful Cray XC-40 machine with a dragonfly interconnect at HPE’s benchmark center. Each node was comprised of Intel Broadwell 2.1 GHz processors with 128GB DDR4-2400 memory. The Lustre file system (model L300) provided 1.4 PB in size. The machine tested was a supercomputer comprised of 700 nodes.


