

Using Altair Grid Engine with NVIDIA Docker
GPUs play an important role in HPC accelerating applications from molecular dynamics to deep learning. In previous articles, we’ve discussed how Altair Grid Engine supports efficient scheduling of GPU resources. We’ve also covered Altair Grid Engine support for Docker and Singularity. In this article, I’ll put these concepts together and explain how NVIDIA Docker simplifies the deployment of GPU-enabled, containerized applications in clustered environments.
What problem does NVIDIA Docker solve?
Most readers appreciate the role that Docker plays in making applications portable. As a reminder, Docker provides a convenient way to package up applications along with dependencies such as binaries and libraries so that they are portable across any host running the Docker Engine. Major Linux distributions have support Docker since 2014. Altair Grid Engine extends these capabilities to clustered environments enabling users to transparently submit, manage and monitor containerized applications just like any other workload. Altair Grid Engine manages details like placing jobs optimally, prioritizing workloads, handling exceptions, and ensuring that required Docker images are available on hosts with appropriate resources on our behalf.
One of the challenges GPU-aware applications inside containers is that containers meant to be hardware agnostic. CUDA is NVIDIA’s parallel computing platform and API that makes it easy for developers to build GPU-enabled applications. GPU-enabled applications need access to both kernel-level device drivers and user-level CUDA libraries, and different applications may require different CUDA versions.
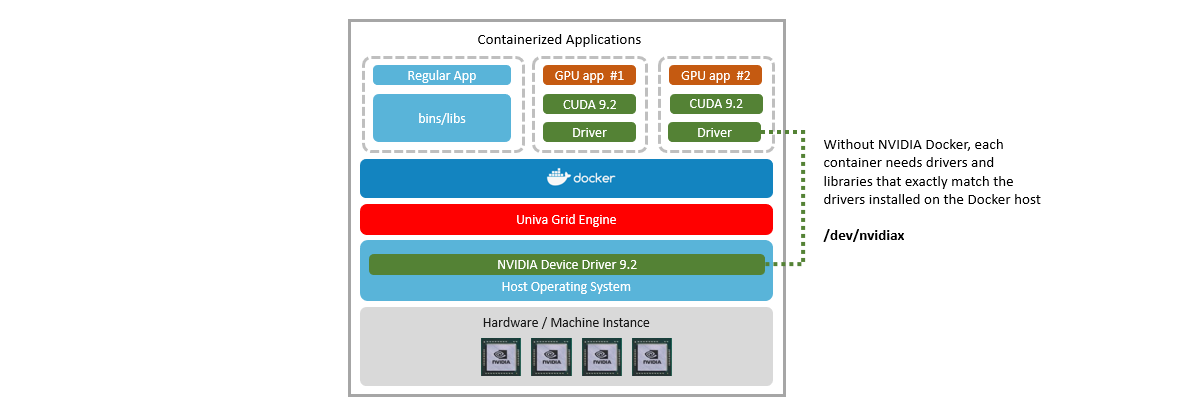
One way to solve this problem is to install the NVIDIA driver inside the container and map the physical NVIDIA GPU device on the underlying Docker host (e.g.,/dev/nvidia0) to the container as illustrated above. The problem with this approach is that the version of the driver and libraries inside the container need to precisely match. Otherwise the application will fail. This means that users are back to worrying about what drivers and libraries are installed on each host computer to ensure compatibility with containerized applications.
About NVIDIA Docker
To solve the problem of containerizing GPU applications, Nvidia developed NVIDIA Docker, an open-source project that provides driver-agnostic CUDA images. The NVIDIA Docker plug-in enables GPU applications running in containers to share GPU devices on the Docker host without worrying about version mismatches between libraries and device drivers.
The figure below shows how this works in a Altair Grid Engine environment. Different cluster hosts may be running different GPU hardware and even different versions of CUDA runtimes and device drivers. Ideally, it should be possible to support containerized apps that support different versions of CUDA on the same host.

Setting up NVIDIA Docker on your Altair Grid Engine cluster
Now that the value of NVIDIA Docker is clear, you may want to take advantage of it on your Altair Grid Engine cluster. Some readers may already have working Altair Grid Engine clusters with GPUs installed. Others may be starting from scratch. The guide below omits some details but provides a roadmap to get NVIDIA Docker working with Altair Grid Engine.
Make sure you have a cluster with GPU capable compute hosts
If you plan to run GPU applications, you’ll need hardware with GPUs. If you don’t have GPU capable hosts, you can rent machine instances in the cloud for a few dollars per hour. To construct the examples below, I used AWS EC2 P3 Instances. These cloud instances support up to 8 NVIDIA v100 GPUs per machine. A relatively inexpensive p3.2xlarge instance with a single 16GB GPU is available on-demand for $3.06 per hour.
There are at least three ways to build a Altair Grid Engine cluster in the AWS cloud (that I can think of):
- Install cluster hosts yourself using the AWS Web UI or AWS CLI and install Altair Grid Engine manually. If you take this path, you know what you’re doing.
- If you’re looking for an easier solution, you can do what I did and deploy an Altair Grid Engine cluster using Altair’s AWS Marketplace offering.
- If you are looking for a simpler but more customized solution contact Altair and we can provide you with a customized Navops Launch.
The AWS Marketplace will deploy a single master host based on an Altair supplied AMI. Once the master is installed, you can log in to the master via ssh and use Navops Launch to add (or remove) cluster hosts using a single command via the built-in AWS resource connector. The Altair AWS marketplace documentation provides step-by-step instructions.
After installing the master host, but before adding compute hosts, use the Navops Launch command below from the Altair Grid Engine master to show how the AWS resource adapter is configured.
By default, Navops Launch with the AWS adapter will add m4.large compute hosts when you expand the AWS cluster. You’ll want to change the default instance type to p3.2xlarge (because these instances have NVIDIA Tesla V100 GPUs) as shown.
root@ip-172-31-75-131 ~]# adapter-mgmt show --resource-adapter=aws --profile=default Resource adapter: aws Profile: default Configuration: - allocate_public_ip = true - ami = ami-9b7183e6 - awsaccesskey = <REDACTED> - awssecretkey = <REDACTED> - cloud_init_script_template = aws_cloud_init.yaml.j2 - instancetype = m4.large - keypair = gridengine - securitygroup = sg-0a0ff570763e417bb - subnet_id = subnet-5dc9bd38
- tags = Name="UGE compute node"
Source: https://gist.githubusercontent.com/GJSissons/570d980ebbb3989b6cb533a8e7238bc8
You can now add one or more compute hosts shown.
[root@ip-172-31-75-131 ~]# add-nodes --count 1 --software-profile execd --hardware-profile aws Add host session [aa01c056-1460-43c4-b550-ec1640de4dd0] created successfully.
Use 'get-node-requests -r aa01c056-1460-43c4-b550-ec1640de4dd0' to query request status
Source: https://gist.githubusercontent.com/GJSissons/4f5ab87350cc120047f6003741de5381
Make sure that you run get-node-requests to check the status of the request. The availability of V100 instances is limited, and availability varies by region so you will want to see any error message or exceptions.
After you’ve added GPU capable compute nodes to your cluster you can verify that they are up and running:
HOSTNAME ARCH NCPU NSOC NCOR NTHR NLOAD MEMTOT MEMUSE SWAPTO SWAPUS ---------------------------------------------------------------------------------------------- global - - - - - - - - - - ip-172-31-71-110 lx-amd64 8 1 4 8 0.02 59.8G 733.4M 0.0 0.0 ip-172-31-72-136 lx-amd64 8 1 4 8 0.02 59.7G 733.5M 0.0 0.0
ip-172-31-72-110 lx-amd64 8 1 4 8 0.01 58.7G 714.5M 0.0 0.0
Source: https://gist.githubusercontent.com/GJSissons/d46c029f4c38eca6936e56f10773304a
Three p3.2xlarge on-demand compute hosts on AWS as shown here will cost approx $10 per hour or approx $1,500 per week, so be careful you don’t keep them running too long!
Install CUDA Drivers on each Altair Grid Engine host
Because I used the Altair Grid Engine AMI (running CentOS), my AWS-based compute hosts didn’t have the NVIDIA CUDA drivers. You’ll need to install the appropriate NVIDIA drivers for your OS release.
Detailed instructions can be found here: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/install-nvidia-driver.html
The rpm to install will depend on your OS version. I’ve skipped a few steps below in the interest of brevity, but I downloaded the publicly available driver for CentOS (listed at https://www.nvidia.com/Download/Find.aspx). The p3.2xlarge AWS instances contain a Tesla V100 GPU as shown below, and the RHEL7 driver is used for CentOS 7.

The Tesla drivers are backward compatible. The V100 driver will also support older P-series, K-series, and C, M, and K class GPUs.
Once you’ve retrieved the rpm format driver you can install the driver on each compute host using the following command:
sudo rpm -i cuda-repo-rhel7-9-2-local-9.2.148-1.x86_64.rpm sudo yum clean all
sudo yum install cuda
Source: https://gist.githubusercontent.com/GJSissons/18c6c60eb2f0afbcb65baa2b729b0a78
The Tesla drivers are backward compatible. The V100 driver will also support older P-series, K-series, and C, M, and K class GPUs.
Once you’ve retrieved the rpm format driver you can install the driver on each compute host using the following command:
sudo rpm -i cuda-repo-rhel7-9-2-local-9.2.148-1.x86_64.rpm sudo yum clean all sudo yum install cudaSource: https://gist.githubusercontent.com/GJSissons/18c6c60eb2f0afbcb65baa2b729b0a78
Install Docker on the cluster compute hosts
Now that you have a Altair Grid Engine cluster with GPUs the next step is to install Docker on each compute host. We explained this procedure in an earlier article so I won’t repeat all the details here, but the script below (should) install Docker on the Grid Engine cluster hosts.
#!/bin/bash # # Install docker on Grid Engine compute host # yum install -y yum-utils \ device-mapper-persistent-data \ lvm2 yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo yum install -y --setopt=obsoletes=0 \ docker-ce-17.03.0.ce-1.el7.centos \ docker-ce-selinux-17.03.0.ce-1.el7.centos
You can find details on installing Docker Community Edition on CentOS here.
Install NVIDIA Docker plug-in on cluster hosts
Now that you have working GPU cluster hosts and have installed Docker on each host, the next step is to install NVIDIA Docker on each host. Detailed installation instructions are available at https://github.com/nvidia/nvidia-docker/wiki/Installation-(version-2.0).
The script below worked for my CentOS 7 compute hosts. The first few lines add the nvidia-docker repositories. Next, yum is used to install nvidia-docker2 and we restart the docker daemon on each host to recognize the nvidia-docker plugin.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | \ sudo tee /etc/yum.repos.d/nvidia-docker.repo # Install nvidia-docker2 and reload the Docker daemon configuration sudo yum install -y nvidia-docker2 sudo pkill -SIGHUP dockerd
Source: https://gist.githubusercontent.com/GJSissons/9a465e01861317c58898304b7e4397fa
Next, we can verify that nvidia-docker is working by running a GPU-enabled application from inside a nvidia/cuda Docker container. The nvidia/cuda container (available from Docker Hub) includes the CUDA toolkit. Packaged GPU applications are typically based on this container.
The command below again runs nvidia-smi, but this time inside the nvidia/cuda container pulled from Docker Hub.
The --runtime=nvidia switch on the docker run command tells Docker to use the NVIDIA Docker plugin.
[root@ip-172-31-64-20 bin]# docker run –-runtime=nvidia --rm nvidia/cuda nvidia-smi Using default tag: latest latest: Pulling from nvidia/cuda d54efb8db41d: Pull complete f8b845f45a87: Pull complete e8db7bf7c39f: Pull complete 9654c40e9079: Pull complete 6d9ef359eaaa: Pull complete cdfa70f89c10: Pull complete 3208f69d3a8f: Downloading 151.3 MB/421.5 MB eac0f0483475: Download complete 4580f9c5bac3: Verifying Checksum 6ee6617c19de: Downloading 109 MB/456.1 MB Wed Nov 21 21:17:13 2018 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.37 Driver Version: 396.37 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... Off | 00000000:00:1E.0 Off | 0 | | N/A 43C P0 39W / 300W | 0MiB / 16160MiB | 5% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
Source: https://gist.githubusercontent.com/GJSissons/9c26f576125563baf18d5b2f64d43bb9
If you’ve gotten this far, congratulations – you now have NVIDIA Docker installed and working on your Altair Grid Engine cluster.
NVIDIA Docker with Altair Grid Engine
Now that Nvidia Docker is working on compute hosts, the next step is to submit NVIDIA Docker containers as Altair Grid Engine jobs. The advantage of running containers under Grid Engine is that the scheduler figures out the optimal place to run containers so that multiple applications and users can share GPU-resources.
Altair Grid Engine provides specific enhancements for running NVIDIA Docker. You can use the -xd switch in Altair Grid Engine to pass the --runtime=nvidia argument as well as any environment variables that need to be accessible within the Docker container.
A sample command showing how NVIDIA Docker containerized applications can be submitted to a grid engine cluster is shown below:
qsub -l docker,docker_images="*tensorflow:18.03-py2*",gpu=1[affinity=true],name=”Tesla V100-PCIE-16GB” \ -xd “--runtime=nvidia” -b y -S /bin/sh <command-inside-container>
Source: https://gist.githubusercontent.com/GJSissons/f4e0aa91934a2ccd91514f7cf9ab9901
- The -l switch indicates that we need to run on cluster hosts with the docker resource set to true (set automatically by Altair Grid Engine when Docker is installed) and requests that a container be created based on the “tensorflow:18.03-py2” image. We also indicate that a GPU-enabled host is required and that we require CPU cores to be bound to a socket connected to the requested Tesla V100 GPU.
- The -xd switch is used to pass the --runtime=nvidia argument to docker on the selected Altair Grid Engine compute host
- The -b y switch indicates that rather than passing a script for execution, we are invoking a binary command already inside the container.
- Normally the shell started inside the container would correspond to the shell defined in the queue, but since the container may not contain the /bin/bash shell we specify -S /bin/sh to start the more standard bourne shell instead of the born-again shell (bash).
- The command inside the container is a path to a script or binary already resident in the container or a path mounted inside the container available on the host (for example /projects/NGC/tensorflow/nvidia-examples/cnn/nvcnn.py)
There are a variety of pre-packaged GPU applications available from NGC (Nvidia’s GPU Cloud). With Docker and NVIDIA Docker installed on Altair Grid Engine GPU hosts, you can use the approach explained above to run GPU-enabled application (with some limits of course) without worrying about compatibility with underlying device drivers.
Have you been using NVIDIA Docker with Altair Grid Engine? We’d love to get your comments and hear about your experiences. You can learn about Altair Grid Engine at https://www.altair.com/grid-engine.


