

Altair CFD™ Capabilities
Altair CFD includes all the major CFD technologies under a single license. It enables engineers to solve all fluids problems regardless of their industry, level of expertise, or application. Altair CFD includes different solvers with distinct features and capabilities.
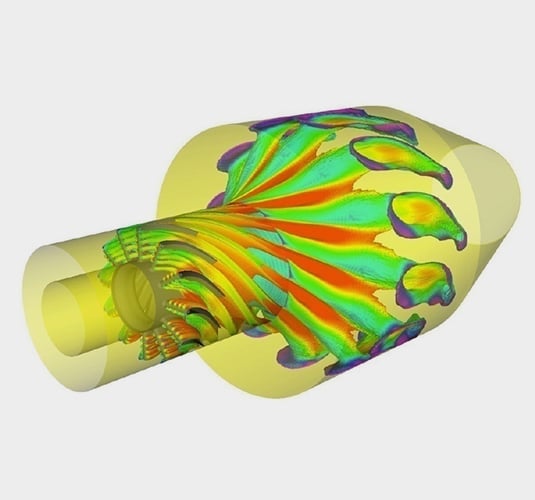
General-purpose Navier-Stokes (NS) Solver
A proven asset for companies looking to explore designs by applying a full range of flow, heat transfer, turbulence, and non-Newtonian material analysis capabilities without the difficulties associated with traditional CFD applications. Robust, scalable, and accurate regardless of the quality and topology of the mesh elements.
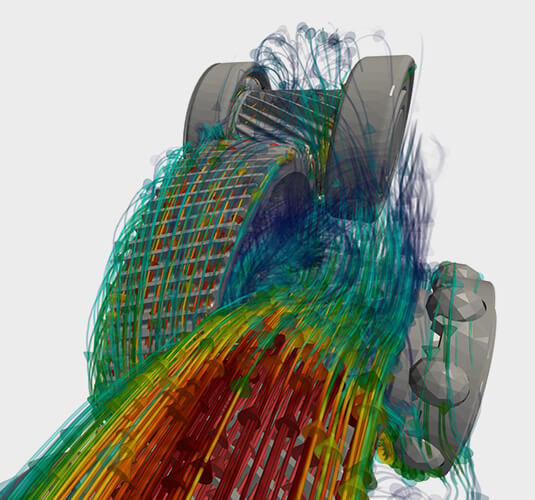
Smoothed-particle Hydrodynamic (SPH) Solver
Used to predict free-surface or multiphase flow behavior in the presence of complex moving geometries or extreme flow deformation (sloshing and mixing). Optimized for use on graphics processing units (GPUs), ensuring minimal turn-around time.
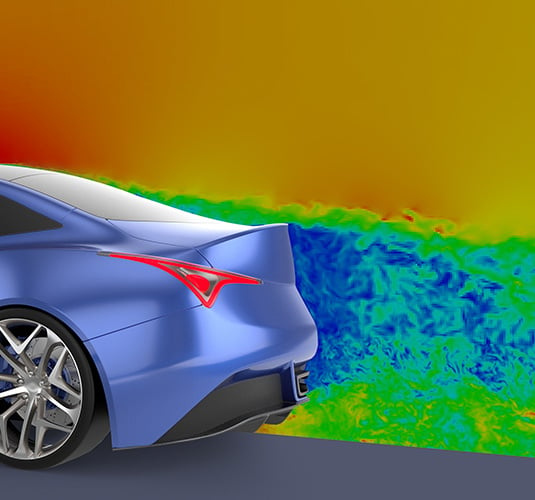
Lattice Boltzmann Method (LBM) Solver
Enables ultra-fast prediction of aerodynamic properties in passenger and heavy-duty vehicles, and for building and environmental aerodynamics. Resolve highly transient aerodynamics simulations overnight on a single server.
General-purpose NS Solver (Altair® AcuSolve®) Features
Implicit Solver
Implicit time stepping enables users to take larger time steps while maintaining accuracy.
Second-order Accurate in Space and Time
The solver is second-order accurate in space and time, without needing to initiate the model with first-order simulation.
Coupled Velocity and Pressure
Quickly solves coupled velocity and pressure systems while maintaining stability.
Steady State Time Marching
Steady state convergence is reached quickly, for many problems in fewer than 100 iterations, increasing simulation throughput.
Stable Long Transient Analysis
Simulate thermal events to their completion with confidence: unparalleled stability during long transient analyses.
Insensitivity to Mesh Quality
No perfect mesh is required unlike other CFD codes where mesh quality affects accuracy and reliability.
Minimum CFL Constraints
Not constrained by traditional Courant-Friedrichs-Lewy (CFL) parameter limitations.
Massively Scalable
The architecture leverages massively parallel machines and scales reliably for every simulation need.
GPU Accelerated
Speed is further enhanced by exploiting locally available resources through GPU acceleration.
SPH Solver (Altair® nanoFluidX®) Features
Simplified Pre-processing
No need for mesh in a classic sense. Import the geometry, select the element, and generate the particles. No more hours of pre-processing and devising a good-enough mesh.
General Free-surface Flows
Simulate sloshing of oil in powertrain systems, free flowing fluids in an open environment, open or closed tanks under high accelerations and similar phenomena.
High-density Ratio Multiphase Flows
The SPH method enables easy treatment of high-density ratio multiphase flows (e.g. water-air) without additional computational effort.
Tank Sloshing
Accurate measurement of the forces experienced by the tank or vehicle during drastic acceleration, like braking or sudden lane change, by tank sloshing simulation.
Rotating Motion
Options available for prescribing different types of motion, therefore simulating rotating gears, crankshafts, and connecting rods in powertrain applications comes easy.
Rigid Body Motion
Besides rotational motion, the code allows for element trajectories prescribed by an input file. Study the interaction of an arbitrary translationally moving solid and the surrounding fluid.
LBM Solver (Altair® ultraFluidX®) Features
High-fidelity External Aerodynamics
A low-diffusive LBM implementation in combination with recent wall models provides high fidelity for transient external aerodynamics.
Native GPU Implementation
A native GPU-based code that naturally leverages the massive power and memory bandwidth of modern GPUs.
Truly Rotating Geometries
Overset mesh functionality enables modeling of truly rotating geometries while maintaining overnight simulation capabilities.
Automated Meshing Process
A fully automated volume mesh generation with low surface mesh requirements and support for intersecting parts makes part replacements easy and allows for quick evaluation of hundreds of configurations.
Fast and Easy Case Setup
Seamless integration into the Altair pre-processing tools and the option to directly modify the solver input deck makes setting up a simulation trivial.
Efficient Result Analysis
Enhanced post-processing features allow extraction of relevant simulation data with a reduced memory footprint while focusing on only the relevant regions of the computational domain.
