
Introduction to Panopticon Streams: Stream Processing with No Coding
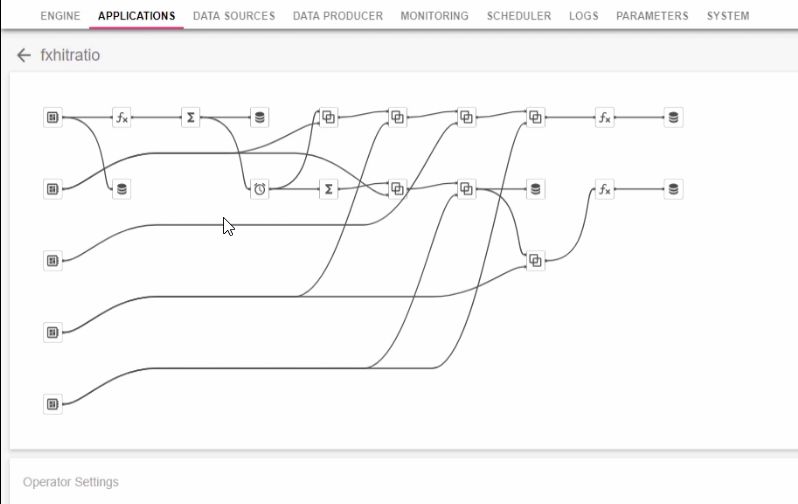
Panopticon Streams, a stream processing engine built on the popular Apache Kafka platform, enables business users to build sophisticated Kafka data flows with no coding. Streams connects directly to a wide range of streaming and historic information sources, including Kafka, Kx kdb+, Solace, Hadoop and NoSQL sources. Streams supports critical data functions including:
- Streaming Data Prep: Combines multiple real-time streams with historic data sources
- Calculation Engine: Calculates performance metrics based on business needs
- Aggregation Driver: Combines data as needed
- Alerting Engine: Highlights anomalies against user-defined thresholds
- Integration with the Confluent Enterprise Control Center
- Expanded support for IoT environments, including manufacturing, energy/utilities, and transportation/logistics
The engine is designed to be used by people who understand their business problems. They can create their own data flows utilizing data from any number of sources and incorporate joins, aggregations, conflations, calculations, unions, merges, and alerts into their stream processing applications. They can then visualize processed data using Panopticon Visual Analytics and/or output it to Kafka, Kx kdb+, InfluxDb, or any SQL database.